Craft CMS trifft auf hohe Skalierbarkeit – eine Reise ins Unbekannte
Wir lieben Craft CMS – so viel steht fest. Es ist ein ausgezeichnetes Content Management System mit einem engagierten Entwicklungs-Team, dessen Flexibilität die exakte Anpassung an unsere Bedürfnisse ermöglicht. Egal ob Headless oder mit der klassischen Herangehensweise durch Twig Templates – wir haben Craft CMS bereits in vielen unserer Projekte verwendet, und werden dies auch in Zukunft gerne tun. Allerdings gibt es einen Bereich, in dem unser Lieblings-CMS nicht auf Anhieb brilliert, und das ist Skalierbarkeit. Dieser Blogpost soll einige der Probleme bei der Skalierung von Craft CMS aufzeigen, und Lösungen zu deren Behebung anbieten.
I'll take your brains to another dimension – pay close attention.
Alles beginnt mit "Dimension". In unserem Fall ist die Dimension von drei wichtigen Kennzahlen gemeint: Multisites, Entries und Assets. Für jede dieser Kennzahlen – aber besonders für die erste – wächst die Komplexität der gesamten Seite exponentiell zu dessen Anstieg.
Lass uns jedoch einen Schritt zurück gehen: um welches Projekt handelt es sich? Gibt es ein praktisches Beispiel dafür? In der Tat, und zwar die Webseite des Bistum Passau, verfügbar auf https://www.bistum-passau.de. Zugegeben, die Hauptseite sieht nicht besonders kompliziert aus, aber die wahre Komplexität liegt in der großen Anzahl an Subseiten wie z.B. https://djk.bistum-passau.de oder https://pfarrverband-passau-st-anton.bistum-passau.de. Obwohl dies in sich abgeschlossene und voneinander isolierte Seiten sind, so liegen sie doch alle in derselben Installation von Craft CMS – mehr als 70 Multisites sind hier eingepflegt. Zusammen mit über 6.700 Entries und über 21.000 Assets sind wir mit einem außerordentlichen System konfrontiert.
Und was braucht ein außerordentliches System? Genau, einen außerordentlichen Server. In unserem Fall haben wir eine Maschine mit 8 fest zugeordneten CPU-Kernen, 32 GB Arbeitsspeicher und 160 GB Festplattenspeicher im Einsatz, auf der einzig und allein das Craft CMS des Bistum Passau läuft. Anfragen werden über NGINX in Zusammenarbeit mit PHP 7.2 verarbeitet, welche wiederum mit MySQL 8.0 und einer Datenbank mit mehreren GB verknüpft sind. Vielleicht wird es jetzt klarer, mit was wir es eigentlich zu tun haben.
An und für sich ist es kein Problem, eine Webseite dem*der Benutzer*in zur Verfügung zu stellen. Komplizierter wird es aber, wenn dieselbe Seite an hunderte oder tausende Benutzer*innen gleichzeitig ausgeliefert werden soll. Aufgrund der neuartigen und besonderen Situation der letzten Wochen ist die problemlose Bereitstellung von Content im Internet wichtiger denn je – was wiederum zusätzliche Herausforderungen für die Ersteller*innen dieses Contents in sich birgt. Und da die Heilige Messe nicht mit physischer Präsenz gefeiert werden konnte, ist das technisch raffinierte Bistum Passau kurzerhand auf Livestreams umgestiegen.
Alles noch immer kein allzu großes Problem – wäre da nicht Ostern. So stieg die Anzahl der Benutzer*innen nicht nur wegen den bereits erwähnten Umständen deutlich an, sondern auch wegen dem für viele Christ*inn*en heiligsten Fest der Auferstehung. Für uns bedeutete dies allerdings rasant steigende Besucher*innenzahlen (ja sogar Benutzer*innenrekorde), die wir in Kombination mit einem bereits komplexen System unter Kontrolle bekommen mussten. Keine einfache Aufgabe – aber eine, die wir schließlich lösen konnten. Wie wir das geschafft haben? Das sehen wir uns jetzt mal genauer an.

Kapitel 1: Bewältigung hoher Benutzer*innenzahlen
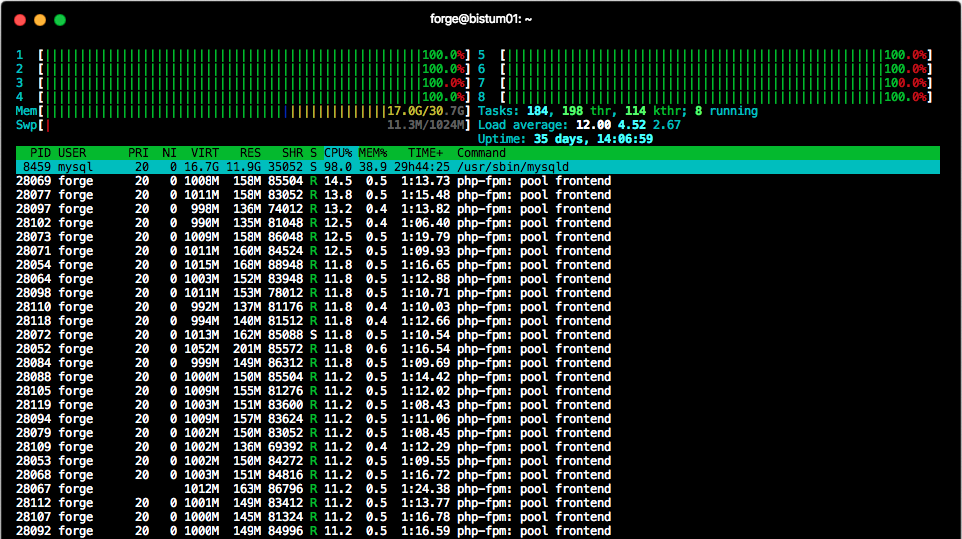
Zu allererst mussten wir uns mit der beständig steigenden Anzahl an Benutzer*innenzugriffen, mit der wir in den Wochen vor Ostern konfrontiert waren, beschäftigen. Nach einer gründlichen Recherche und genauer Beobachtung unseres Systems konnten wir feststellen, dass gecachte Seiten von Craft in die Datenbank geschrieben und bei einem Benutzer*inzugriff von dort abgeholt werden. Finden nun hunderte Zugriffe gleichzeitig statt, so muss der MySQL-Prozess jedes Mal auf die Datenbank zugreifen und konsumiert daher einen erheblichen Teil der verfügbaren CPU, während der Rest von PHP-Prozessen verbraucht wird (siehe Grafik überhalb dieses Paragraphs). Aufgrund dessen steht dem NGINX-Webserver nicht genug Rechenleistung zur Verfügung, womit ein Benutzer*inzugriff früher oder später mit den Fehlermeldungen 502 Bad Gateway bzw. 504 Gateway Timeout fehlschlägt.
Unsere erste Idee war ein Upscale des Servers. Dieser Upscale half jedoch nur bedingt, da die MySQL-Abfrage noch immer viel zu viel CPU in zu kurzer Zeit konsumierte. Somit mussten wir etwas um die Ecke denken und uns nach einer besseren Lösung umsehen.
Unsere nächste Idee war Statisches HTML-Caching. Obwohl dies auf den ersten Blick mit der Flexibilität eines Content Management Systems nicht vereinbar scheint, so macht dieser Gedanke doch sehr viel Sinn, wenn man eine große Anzahl an Benutzer*inne*n auf derselben Seite erwartet – in unserem Fall besuchte die Mehrheit der Benutzer*innen tatsächlich dieselben paar Livestream-Seiten. Wenn man nun diese Seiten bereits vor dem Ansturm als Statisches HTML vorbereitet, so muss der MySQL-Prozess keine Anfrage an die Datenbank schicken, was wiederum dem NGINX viel Rechenleistung zur Verfügung stellt, um ankommende Anfragen rasch abzuarbeiten. Nachdem wir diese Überlegung mit dem ausgezeichneten Blitz Plugin umgesetzt hatten, konnten wir problemlos mehrere hundert Benutzer*innenzugriffe gleichzeitig abarbeiten, ohne den Server an den Rand des Kollaps zu treiben.
Der einzige Nachteil bei dieser Herangehensweise war, dass Änderungen aus dem CMS in den gecachten Seiten erst aufscheinen, wenn der Cache neu erstellt wird. Da wir Statisches HTML jedoch nur für einige wenige Seiten nutzen und den Cache ohnehin bei jedem Deploy sowie ein Mal pro Nacht mit einem Cron Job neu erstellen lassen, hatte dieses Manko keine negativen Auswirkungen auf unser System. Zwar ist die exakte Strategie, was man wann cachen sollte, abhängig von den jeweiligen Anforderungen des Projekts, aber für uns wirkte diese Lösung Wunder im Hinblick auf schnelle und problemlose Bereitstellung der Frontend-Templates für unsere Benutzer*innen.
Kapital 2: Lass uns tunen!
Es ist wohl keine Überraschung, dass ein Upscale eines Servers nicht die einzige Möglichkeit ist, um ein System schneller bzw. besser zu machen. Bei jedem Server gibt es unzählige kleine Schrauben, an denen gedreht werden könnte. Aus Gründen der Übersichtlichkeit werden wir uns hier allerdings nur auf die wichtigen Ideen konzentrieren. Und – da wir bis jetzt nicht wirklich nerdy waren – wird dieses Kapitel zum Großteil aus Code bestehen. Zu den folgenden Snippets muss jedoch hinzugefügt werden, dass diese speziell auf unsere Anforderungen zugeschnitten sind und nur Ausschnitte der jeweiligen Konfigurationen darstellen. Deswegen sei Vorsicht beim Copy-Pasting geboten.
Unsere erste Verbesserung war die Aufteilung der Kommunikation zwischen NGINX und PHP in zwei verschiedene Sockets – einen für das Frontend und einen für das Backend. Diese Trennung soll sicherstellen, dass das Backend ganz normal weiterarbeiten kann, wenn das Frontend beschäftigt ist (und umgekehrt). Jedoch genug der Worte, sehen wir uns den Code genauer an:
# NGINX Config Snippet
# /etc/nginx/sites-available/www.bistum-passau.de
set $fpm_socket "unix:/var/run/php/php7.2-fpm-frontend.sock";
if ($uri ~* "^/admin/") {
set $fpm_socket "unix:/var/run/php/php7.2-fpm-backend.sock";
}
# PHP Pool Config Snippet
# /etc/php/7.2/fpm/pool.d/www.conf
[frontend]
user = forge
group = forge
listen = /run/php/php7.2-fpm-frontend.sock
listen.owner = www-data
listen.group = www-data
listen.mode = 0666
pm = static
pm.max_children = 64
pm.max_requests = 3000
request_terminate_timeout = 3600
[backend]
user = forge
group = forge
listen = /run/php/php7.2-fpm-backend.sock
listen.owner = www-data
listen.group = www-data
listen.mode = 0666
pm = static
pm.max_children = 64
pm.max_requests = 3000
request_terminate_timeout = 3600
Die zweite Verbesserung ist nicht sofort ersichtlich, befindet sich aber direkt in oberem PHP Pool Config Snippet: warum verwenden wir pm = static anstatt pm = dynamic oder pm = ondemand? Die Antwort darauf ist, dass bei den letzten beiden Varianten nur eine kleine Anzahl an PHP-Prozessen ständig existiert – der Rest muss erst erstellt werden, wenn ein plötzlicher Anstieg an Benutzer*innenzugriffen auftritt. Und genau diese Zeit, die es dauert, um die notwendigen PHP-Prozesse neu zu erstellen, kann bei einem System über Erfolg oder Misserfolg entscheiden. Mit unserem Server können wir problemlos 64 * 2 = 128 PHP-Prozesse nebeneinander laufen lassen, die im Falle des Falles sofort ihre Arbeit verrichten können. Auch hier gilt wieder, dass die maximale Anzahl an PHP-Prozessen und Requests von System zu System unterschiedlich ist – diese soeben genannte Anzahl ist jedoch in unserem Fall ein guter Kompromiss.
# PHP Config Snippet
# /etc/php/7.2/fpm/php.ini
max_execution_time = 300
max_input_time = 300
max_input_vars = 10000
memory_limit = 8G
default_socket_timeout = 300
mysql.connect_timeout = 300
mysql.allow_persistent = 1
# MySQL Config Snippet
# /etc/mysql/mysql.cnf
innodb_buffer_pool_size=8G
innodb_log_files_in_group=2
innodb_log_file_size=1G
innodb_flush_log_at_trx_commit=0
innodb_thread_concurrency=4
innodb_stats_on_metadata=0
max_allowed_packet=512M
wait_timeout=300
net_read_timeout=300
net_write_timeout=300
interactive_timeout=300
connect_timeout=300
Zu guter Letzt werfen wir noch einen Blick auf die oberen PHP und MySQL Config Snippets. Für PHP sind die wichtigsten Parameter max_execution_time and memory_limit. Es ist ratsam, die maximale Ausführungszeit nicht zu hoch anzusetzen – es bringt nichts, das System allzu lange probieren zu lassen, ein auftretendes Problem zu lösen. Das Limit des Arbeitsspeichers jedoch kann – je nach verfügbarem RAM – höher angesetzt werden. Wichtig hierbei ist nur, denselben Wert auch in der General Config von Craft CMS bei dem Parameter phpMaxMemoryLimit einzustellen. Es wäre schade, wenn PHP großzügig Arbeitsspeicher benutzen dürfte, das CMS allerdings die Benützung dessen einschränkten würde.
Bei MySQL interessieren uns die Parameter innodb_buffer_pool_size und max_allowed_packet am meisten. Wir konnten gute Ergebnisse erzielen, indem wir den ersten Parameter ähnlich dem Limit des Arbeitsspeichers gesetzt haben. Der Wert des zweiten Parameters hängt stark davon ab, welche Packages hin und her geschickt werden. Sollten Fehler wie "Packet Too Large" auftreten, so können diese durch dessen Anpassung korrigiert werden.
Kapitel 3: Queue ist nicht nur für Billard
Nachdem wir sichergestellt hatten, dass Benutzer*innen unsere Webseite problemlos ansurfen können und unser Server wie ein Kätzchen schnurrt, mussten wir uns noch um unsere Content-Editor*inn*en kümmern. Besonders das Editieren von Entries und Assets sollte im operativen Gebrauch so wenig Probleme wie möglich bereiten. Eine Sache, die eigentlich im Hintergrund agiert, ist dafür sehr wichtig: die Queue.
Sobald ein Entry oder Asset erstellt / gespeichert / gelöscht wird, wird eine mehr oder minder große Anzahl an Queue Jobs angestoßen. Egal ob es sich um das Erneuern von Suchindizes, um das Löschen von abgelaufenen Template Caches oder um die Generierung von Sitemaps handelt: all diese Aktionen werden von Queue Jobs erledigt. Dass deren Anzahl mit über 70 Multisites und Tausenden von Entries und Assets exponentiell ansteigt, ist an dieser Stelle wohl nicht verwunderlich. Und bevor wir es noch länger verheimlichen: ja, wir hatten Probleme mit unserer Queue. Enorme Probleme.
Zum größten Teil sind diese Probleme aufgetreten, weil Queue Jobs mit der gleichen Priorität behandelt wurden wie andere MySQL-Abfragen des CMS. Es ist jedoch verständlich, dass für die Content-Editor*inn*en das schnelle Speichern eines Artikels (auch mit diesem Thema haben wir uns schon beschäftigt, siehe hier) wichtiger ist als das Löschen von abgelaufenen Template Caches. Deswegen ist es eine gute Idee, Queue Jobs tatsächlich im Hintergrund laufen zu lassen. Mit anderen Worten: wir wollen, dass sie "nice" zu anderen Jobs sind und diesen den Vortritt lassen.
Obwohl dies mit einem Plugin erreicht werden kann (als Beispiel sei hier AsyncQueue genannt), so hatten wir uns dennoch dafür entschieden, die Möglichkeiten von Forge – unserem Tool zur Server-Verwaltung – zu nutzen und einen Daemon zu installieren, der alle ankommenden Queue Jobs als "nice" einstuft und sie so im Hintergrund abarbeitet. Dies war leicht einzurichten und ein guter Weg, um eine Async Queue in Craft anzulegen. Hierbei ist es nur wichtig, auch den Parameter runQueueAutomatically in der Craft General Config auf "false" zu setzen, sodass das CMS nicht versucht, die Queue automatisch laufen zu lassen.
# Forge Async Queue Daemon
/usr/bin/nice -n 10 /usr/bin/php /home/forge/www.bistum-passau.de/current/craft queue/listen --verbose
Aber das war nicht alles. Wir wollten die Auswirkung der Queue auf die Datenbank so gering wie möglich halten, sodass andere Prozesse die zur Verfügung stehenden Ressourcen nutzen konnten. Da jeder Queue Job einen neuen Eintrag in der entsprechenden Datenbank-Tabelle angelegt, diesen Eintrag während seiner Bearbeitung periodisch aktualisiert (z.B. mit seinem Fortschritt) und schließlich den Eintrag nach seiner Abhandlung wieder löscht, kann eine nicht zu verachtende Anzahl an MySQL-Abfragen eingespart werden, wenn die Queue woanders ausgeführt wird. Und genau hier kommt Redis ins Spiel.
Redis ist nicht nur Open Source, sondern auch eine In-Memory-Datenstruktur mit Key-Value-Pairing, die als Datenbank, Cache oder Übermittler von Nachrichten verwendet werden kann. Es ist – und das wissen wir nun aus Erfahrung – wahnsinnig schnell und kann alle Queue Jobs problemlos abarbeiten. Da die gesamte Abhandlung der Queue Jobs in Redis passiert, muss nur ein einziger MySQL-Befehl ausgeführt werden, nämlich jener, der das "Ergebnis" in die Datenbank einträgt (indem z.B. ein Suchindex erneuert oder ein abgelaufener Template Cache gelöscht wird).
Ein weiteres Mal stand uns Forge bei der leichten Einrichtung der benötigten Tools zur Seite. Um Redis zum Laufen zu bringen, musste nämlich nur der folgende Code in das Craft Config File app.php eingefügt werden:
# Craft CMS App Config File Snippet
<?php
return [
'*' => [
'components' => [
// Initialize Redis component
'redis' => [
'class' => yii\redis\Connection::class,
'hostname' => 'localhost',
'port' => 6379,
'password' => null,
],
// Use queue with Redis
'queue' => [
'class' => yii\queue\redis\Queue::class,
'redis' => 'redis',
'channel' => 'queue',
],
],
],
];
Tatsächlich gibt es nur einen einzigen Nachteil, der bei der Abhandlung der Queue durch Redis entsteht: der Fortschritt der einzelnen Queue Jobs wird nicht mehr im Control Panel von Craft angezeigt, da es (noch) keine Implementierung dafür gibt. Dies mag sich in Zukunft ändern, aber falls man sich dafür entscheidet, die Queue in Redis auszulagern, so muss der Redis Monitor in der Konsole dafür verwendet werden, um den Fortschritt der einzelnen Queue Jobs zu überprüfen.
Die berühmten letzten Worte
In den vorherigen Kapiteln wurden einige Ideen und Ansätze präsentiert und besprochen. Obwohl diese nicht zwingend für jedes System und jede Konfiguration gleich (gut) funktionieren, so waren sie in unserem Fall nichtsdestotrotz sehr hilfreich und sorgten dafür, dass unser Craft CMS – mit all seinen Komplexitäten – schnell und skalierbar blieb bzw. wurde. Während die Stärke eines CMS definitiv seine Flexibilität ist, so muss diese jedoch nicht zwingend gegen Skalierbarkeit eingetauscht werden. Mit etwas Recherche und Um-die-Ecke-Denken kann man auch Probleme lösen, die aus einer hohen Anzahl an Multisites, Entries und Assets resultieren.
Wir hoffen, dass dieser Artikel interessant und aufschlussreich war, und freuen uns über Inputs und Anregungen zu unseren Gedanken! Gerne auf einem beliebigen Social Media-Kanal, oder auch persönlich bei uns in der Agentur bei einem Feierabend-Bier. :-)